Customizing AI-Powered Insights
This article explains how to customize the AI-powered insights functionality for different use cases. There are two distinct ways to achieve this:
- Configuring the Report Engine—Declarative configuration through application settings.
- Overriding ReportsControllerBase Methods—Programmatic customization with custom logic.
Configuring the Report Engine
The declarative configuration approach handles most common customization scenarios through the AIClient element in your application's configuration file. It allows you to customize user consent, custom and predefined prompts, and RAG optimization without writing any code.
If you haven't configured the report engine previously, make sure to check the article Report Engine Configuration Overview to get familiar with this topic.
User Consent Configuration
By default, the AI Prompt dialog requests explicit consent from users before sending prompts to the AI model. This ensures transparency about data being sent to external AI services and gives users control over their data privacy.
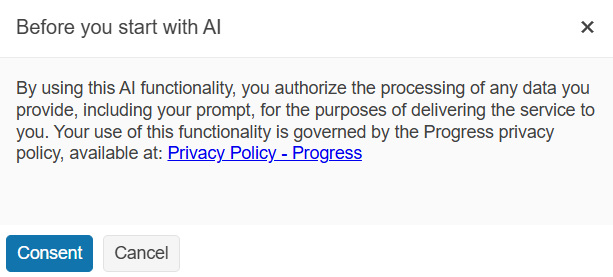
In enterprise environments where AI usage policies are already established or when working with trusted internal models, you may want to streamline the user experience by disabling this consent requirement. In these cases, you can set the requireConsent option to false:
{
"telerikReporting": {
"AIClient": {
"requireConsent": false
}
}
}
<configuration>
<configSections>
<section
name="Telerik.Reporting"
type="Telerik.Reporting.Configuration.ReportingConfigurationSection, Telerik.Reporting"
allowLocation="true"
allowDefinition="Everywhere"/>
</configSections>
<Telerik.Reporting>
<AIClient
requireConsent="false">
</AIClient>
</Telerik.Reporting>
</configuration>
Prompts Configuration
By default, users can create their own custom prompts to ask any questions about their reports. While this provides maximum flexibility, it can lead to unpredictable token usage costs and potentially inconsistent results. In these cases, you can provide the users with predefined prompts that are designed to handle specific tasks.
To restrict users to predefined prompts only, you set allowCustomPrompts to false and add the predefined prompts through the predefinedPrompts option:
{
"telerikReporting": {
"AIClient": {
"allowCustomPrompts": false,
"predefinedPrompts": [
{ "text": "Generate a summary of the report." },
{ "text": "Translate the report into German." }
],
}
}
}
<configuration>
<configSections>
<section
name="Telerik.Reporting"
type="Telerik.Reporting.Configuration.ReportingConfigurationSection, Telerik.Reporting"
allowLocation="true"
allowDefinition="Everywhere"/>
</configSections>
<Telerik.Reporting>
<AIClient
allowCustomPrompts="false">
<predefinedPrompts>
<add text="Generate a summary of the report." />
<add text="Translate the report into German." />
</predefinedPrompts>
</AIClient>
</Telerik.Reporting>
</configuration>
You can also add predefined prompts without disabling custom ones, giving users both curated options and the flexibility to create their own queries.
Retrieval-Augmented Generation (RAG) Configuration
By default, the AI-powered insights functionality uses a Retrieval-Augmented Generation (RAG) algorithm to filter out the irrelevant report data before sending it to the AI model. This approach significantly improves the accuracy and relevance of the AI-generated response while optimizing token usage.
RAG is available only in .NET and .NET Standard. Therefore, the options that are listed below are not supported in .NET Framework configurations.
If needed, you can disable this algorithm by setting allowRAG to false.
You can also configure the RAG behavior through the ragSettings option:
-
modelMaxInputTokenLimit—Limits the maximum input tokens the AI model can process in a single request. The default value is15000. -
maxNumberOfEmbeddingsSent—Limits how many embeddings (chunks of retrieved content) are sent to the model in a single request. The default value is15. -
maxTokenSizeOfSingleEmbedding—Limits token size of each individual embedding, which prevents large chunks from dominating the prompt. The default value is0(no limit). -
tokenizationEncoding—Specifies tokenization scheme used to estimate the tokens usage before sending the request to the LLM model. By default, the encoding is determined automatically based on the specified model, which is recommended to ensure accurate token counting. Incorrect encoding may lead to miscalculations in token limits, causing either premature truncation of context or exceeding the model’s input capacity. -
splitTables—Indicates whether tables should be split during Retrieval-Augmented Generation (RAG) processing. When the splitting is allowed, only the relevant table cells will be taken into account, significantly reducing the number of tokens. The default value istrue.
Below is an example that takes advantage of the table splitting and automatic encoding inference, but reduces the token limits:
"telerikReporting": {
"AIClient": {
"ragSettings": {
"modelMaxInputTokenLimit": 12000,
"maxNumberOfEmbeddingsSent": 10,
"maxTokenSizeOfSingleEmbedding": 2000
}
}
}
For a complete reference of all available AIClient options, check the article AIClient Element Overview.
Overriding ReportsControllerBase Methods
While the declarative configuration handles most common scenarios, some advanced use cases require programmatic customization. You can achieve this by overriding specific methods of the ReportsControllerBase class in your ReportsController. This approach allows you to implement dynamic logic based on user context, report properties, or business rules.
You can override the methods described in the following sections and customize different aspects of the AI-powered insights workflow.
CreateAIThread(string, string, ClientReportSource)
The CreateAIThread(string, string, ClientReportSource) method is called when the AI Prompt dialog is about to be displayed. You can override this method to disable the AI-powered insights functionality entirely. The logic can be tailored based on the currently previewed report, which is represented by the ClientReportSource parameter. For modifying dialog properties like consent messages or predefined prompts, use the UpdateAIPrompts method instead, which provides direct access to the AIThreadInfo object.
.NET
/// <summary>
/// Disables the AI-powered insights functionality dynamically depending on the passed <see cref="ClientReportSource"/> parameter.
/// </summary>
/// <returns></returns>
public override IActionResult CreateAIThread(string clientID, string instanceID, ClientReportSource reportSource)
{
if (reportSource.Report == "report-with-disabled-ai-insights.trdp")
{
return StatusCode(
StatusCodes.Status403Forbidden,
new
{
message = "An error has occurred.",
exceptionMessage = "AI Insights functionality is not allowed for this report.",
exceptionType = "Exception",
stackTrace = (string?)null
}
);
}
return base.CreateAIThread(clientID, instanceID, reportSource);
}
.NET Framework
/// <summary>
/// Disables the AI-powered insights functionality dynamically depending on the passed <see cref="ClientReportSource"/> parameter.
/// </summary>
/// <returns></returns>
public override HttpResponseMessage CreateAIThread(string clientID, string instanceID, ClientReportSource reportSource)
{
if (reportSource.Report == "SampleReport.trdp")
{
var errorResponse = new
{
message = "An error has occurred.",
exceptionMessage = "AI Insights functionality is not allowed for this report.",
exceptionType = "Exception",
stackTrace = (string)null
};
return this.Request.CreateResponse(HttpStatusCode.Forbidden, errorResponse);
}
return base.CreateAIThread(clientID, instanceID, reportSource);
}
UpdateAIPrompts(ClientReportSource, AIThreadInfo)
The UpdateAIPrompts(ClientReportSource, AIThreadInfo) method is called internally during the execution of CreateAIThread(). This is the recommended method for modifying dialog properties like consent messages and predefined prompts, as it provides direct access to the AIThreadInfo object without requiring type casting or result checking.
.NET
/// <summary>
/// Overrides the default user consent message.
/// </summary>
protected override void UpdateAIPrompts(ClientReportSource reportSource, AIThreadInfo aiThreadInfo)
{
aiThreadInfo.ConsentMessage = "By using this AI functionality, you authorize the processing of any data you provide, including your prompt, for the purposes of delivering the service to you. Your use of this functionality is governed by the Progress privacy policy, available at: <a href='https://www.progress.com/legal/privacy-policy'>Privacy Policy - Progress</a>.";
base.UpdateAIPrompts(reportSource, aiThreadInfo);
}
/// <summary>
/// Modifies the collection of predefined prompts.
/// </summary>
protected override void UpdateAIPrompts(ClientReportSource reportSource, AIThreadInfo aiThreadInfo)
{
if (reportSource.Report == "report-suitable-for-markdown-output.trdp")
{
aiThreadInfo.PredefinedPrompts.Add("Create a summary of the report in Markdown (.md) format.");
}
base.UpdateAIPrompts(reportSource, aiThreadInfo);
}
.NET Framework
/// <summary>
/// Overrides the default user consent message.
/// </summary>
protected override void UpdateAIPrompts(ClientReportSource reportSource, AIThreadInfo aiThreadInfo)
{
aiThreadInfo.ConsentMessage = "By using this AI functionality, you authorize the processing of any data you provide, including your prompt, for the purposes of delivering the service to you. Your use of this functionality is governed by the Progress privacy policy, available at: <a href='https://www.progress.com/legal/privacy-policy'>Privacy Policy - Progress</a>.";
base.UpdateAIPrompts(reportSource, aiThreadInfo);
}
/// <summary>
/// Modifies the collection of predefined prompts.
/// </summary>
protected override void UpdateAIPrompts(ClientReportSource reportSource, AIThreadInfo aiThreadInfo)
{
if (reportSource.Report == "report-suitable-for-markdown-output.trdp")
{
aiThreadInfo.PredefinedPrompts.Add("Create a summary of the report in Markdown (.md) format.");
}
base.UpdateAIPrompts(reportSource, aiThreadInfo);
}
GetAIResponse(string, string, string, string, AIQueryArgs)
The GetAIResponse(string, string, string, string, AIQueryArgs) method is called every time a prompt is sent to the AI model. This method provides control over the AI request workflow, allowing you to intercept, modify, and validate requests before they reach the LLM. Below are examples of common customization scenarios.
.NET
/// <summary>
/// Modifies the prompt sent from the client before passing it to the LLM.
/// </summary>
/// <returns></returns>
public override async Task<IActionResult> GetAIResponse(string clientID, string instanceID, string documentID, string threadID, AIQueryArgs args)
{
args.Query += $"{Environment.NewLine}Keep your response concise.";
return await base.GetAIResponse(clientID, instanceID, documentID, threadID, args);
}
/// <summary>
/// Examines the approximate tokens count and determines whether the prompt should be sent to the LLM.
/// </summary>
/// <returns></returns>
public override async Task<IActionResult> GetAIResponse(string clientID, string instanceID, string documentID, string threadID, AIQueryArgs args)
{
const int MAX_TOKEN_COUNT = 500;
args.ConfirmationCallBack = (AIRequestInfo info) =>
{
if (info.EstimatedTokensCount > MAX_TOKEN_COUNT)
{
return ConfirmationResult.CancelResult($"The estimated token count exceeds the allowed limit of {MAX_TOKEN_COUNT} tokens.");
}
return ConfirmationResult.ContinueResult();
};
return await base.GetAIResponse(clientID, instanceID, documentID, threadID, args);
}
/// <summary>
/// Examines whether the RAG optimization is applied for the current prompt.
/// </summary>
/// <returns></returns>
public override async Task<IActionResult> GetAIResponse(string clientID, string instanceID, string documentID, string threadID, AIQueryArgs args)
{
args.ConfirmationCallBack = (AIRequestInfo info) =>
{
if (info.Origin == AIRequestInfo.AIRequestOrigin.Client)
{
System.Diagnostics.Trace.TraceInformation($"RAG optimization is {info.RAGOptimization} for this prompt.");
}
return ConfirmationResult.ContinueResult();
};
return await base.GetAIResponse(clientID, instanceID, documentID, threadID, args);
}
.NET Framework
The RAG Optimization Monitoring example is not included in this section because RAG functionality is available only in .NET and .NET Standard configurations.
/// <summary>
/// Modifies the prompt sent from the client before passing it to the LLM.
/// </summary>
/// <returns></returns>
public override async Task<HttpResponseMessage> GetAIResponse(string clientID, string instanceID, string documentID, string threadID, AIQueryArgs args)
{
args.Query += $"{Environment.NewLine}Keep your response concise.";
return await base.GetAIResponse(clientID, instanceID, documentID, threadID, args);
}
/// <summary>
/// Examines the approximate tokens count and determines whether the prompt should be sent to the LLM.
/// </summary>
/// <returns></returns>
public override async Task<IActionResult> GetAIResponse(string clientID, string instanceID, string documentID, string threadID, AIQueryArgs args)
{
const int MAX_TOKEN_COUNT = 500;
args.ConfirmationCallBack = (AIRequestInfo info) =>
{
if (info.EstimatedTokensCount > MAX_TOKEN_COUNT)
{
return ConfirmationResult.CancelResult($"The estimated token count exceeds the allowed limit of {MAX_TOKEN_COUNT} tokens.");
}
return ConfirmationResult.ContinueResult();
};
return await base.GetAIResponse(clientID, instanceID, documentID, threadID, args);
}