Naming Conventions
This article is relevant to entity models that utilize the deprecated Visual Studio integration of Telerik Data Access. The current documentation of the Data Access framework is available here.
Telerik Data Access uses a default naming strategy for the table and columns name generation. When you use default mapping, the generated relational names will be based on your class and property names. By default, your column names will be based on the property names, i.e. the property names will not be changed. Any casing specified will be kept and no word breaks will be inserted. Also the generated identifier will be trimmed (if needed) so that it can match the maximum allowed length for the backend. All invalid characters like '$', '/' and '.' will be replaced with 'string.Empty'.
To illustrate the default naming rules, consider the following example:
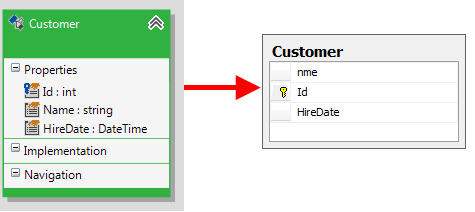
The Customer domain class will be mapped to a table named 'Customer'. And the Customer properties will be mapped to columns as follow:
- Id <-> Id
- Name <-> nme
- HireDate <-> HireDate
The "Name" property will be mapped to a column "nme". This is the default Telerik Data Access behavior, i.e. reserved words will be modified. You can control the naming processing algorithm. For more information, take a look at the next section.
Modifying the Database Naming Settings
Telerik Data Access allows you to specify various naming rules and settings that will be applied on the generated relational items (tables and columns). For example, it is possible to instruct Telerik Data Access to use the field name as it is for the column name. Generally, there are two possible ways for specifying database naming rules. During the process of domain model generation (using the Telerik Data Access New Domain Model wizard). When the selected domain model type is Empty Domain Model, then the second page in the wizard is the Define Relational Naming Settings dialog. In most of the cases, you will use the second approach - via the Model Settings Dialog in the Visual Designer.
You need to modify the database naming settings before mapping your entity by using the default mapping functionality. Once your entity is mapped to a table, changing the database naming settings will not affect the table and the columns.
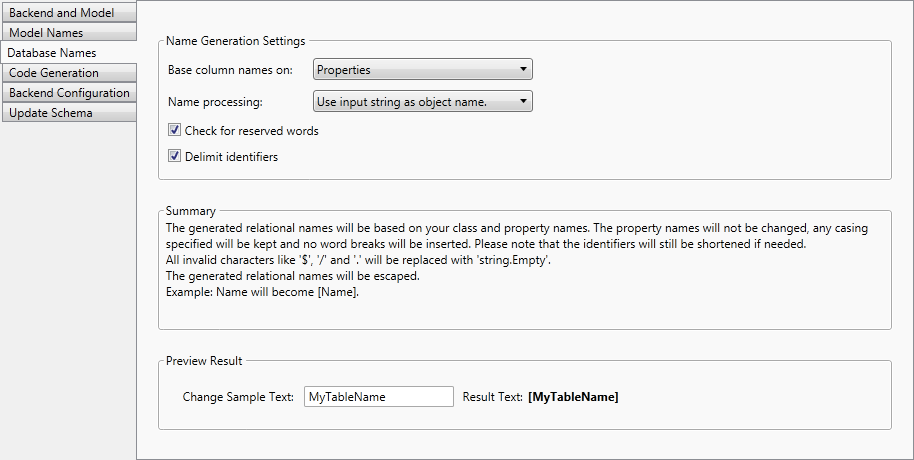
Base Column Names On
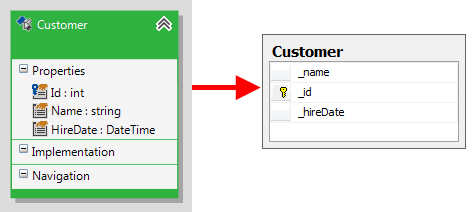
By default all column names will be based on the corresponding property names, but you can modify this. The "Base column names on" setting allows you to choose the source of the column names. You can choose to use either the property names or the field names. For example, if you use the field names:
Name Processing
The name processing option specifies the algorithm that will be used. The "Generate valid object names" setting removes any camel casing from the column name. It will also apply word breaks before each capital letter. This is the default behavior. The "Use input string as object name" option will leave the property/field name as it is. It will not change any casing or apply any word breaks.
Check for reserved words
This option is available only if the selected name processing setting is "Use input string as object name". It controls whether reserved backend words will be replaced with words that are save to use. If the selected name processing setting is "Generate valid object names", then this option is disabled and checked, i.e. check for reserved words is always performed if you are generating valid names and it cannot be turned off.
Delimit Identifiers
This option controls whether the generated database identifiers will be escaped on the server.