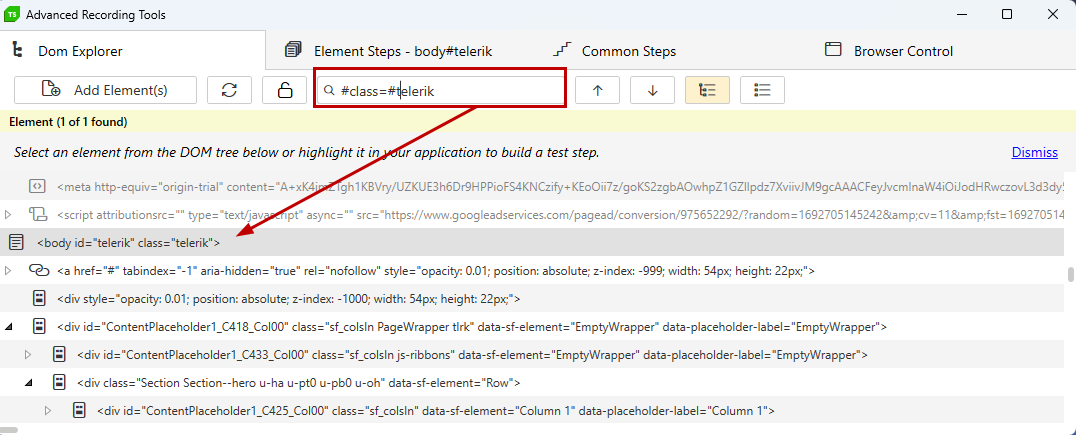
DOM Explorer
The DOM Explorer tab in the Advanced Recording Tools window displays the DOM of the tested application in a tree or tag format. The DOM (Document Object Model) is a language neutral and platform independent abstraction that allows the content, structure and style of HTML pages and desktop applications to be represented dynamically.
Find further details about the DOM Explorer functions:
Test Studio is a test automation platform for web, WPF, and responsive web applications, supporting UI, functional, load, and RESTful API testing. Sign up for a free 30-day trial!
![]()
New to Telerik Test Studio?
Toolbar Options
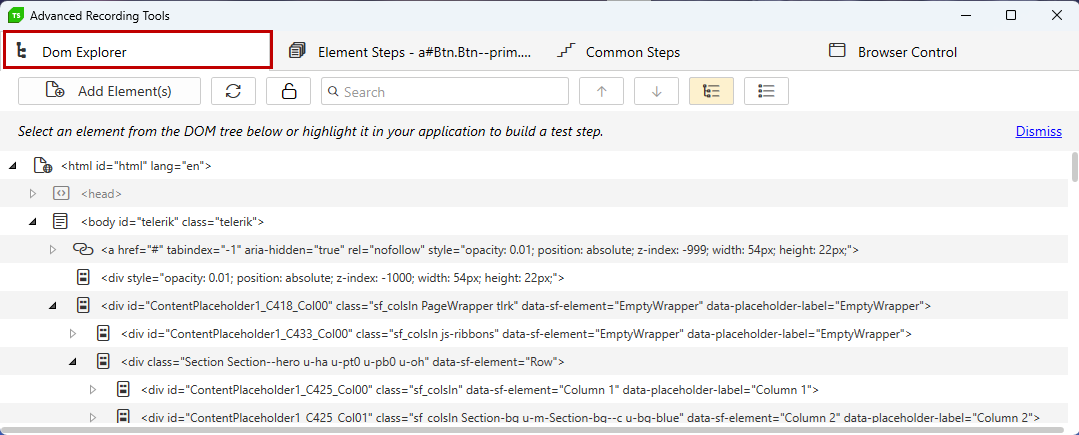
The DOM Explorer tab exposes a set of useful functionalities listed in a toolbar. Find out more for each of these in the below list.
- Add elements
- Refresh elements
- Freeze/Unfreeze elements tree
- Search
- Tree and Tag View
- Parent element filter
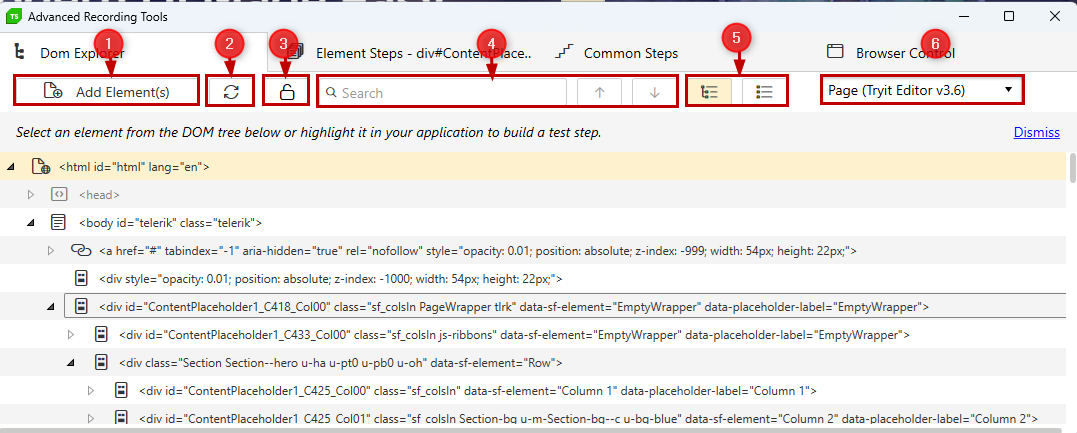
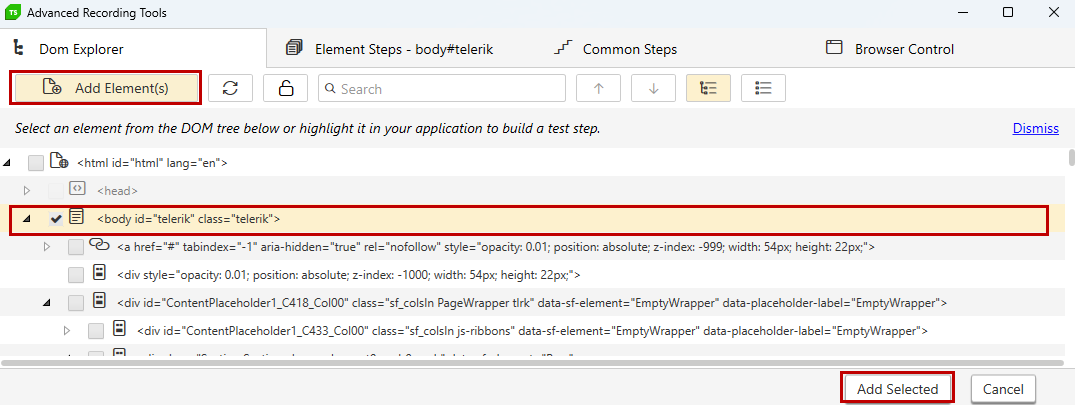
1. Add Element(s)
You can add a single or multiple elements to the project's Elements Explorer. Click the button to activate selection and start selecting the elements from the DOM tree. When you are ready to add them to the elements repository, click the Add Selected button in the bottom right corner of the Advanced Recording Tools window. You can cancel this action by clicking the Cancel button.
2. Refresh Elements Tree
You can manually refresh the elements tree to replicate the current structure of the tested application in the DOM Explorer. This action does not refresh the browser, but only the elements tree that Test Studio recorder uses. Typically used when the elements tree is frozen and there are changes in the DOM tree.
3. Freeze/Unfreeze Elements Tree
Test Studio recorder detects any change in the application and automatically refreshes the DOM tree. This option allows you to pause and resume the auto-refresh of the elements tree. This is useful when there is a control on the page, which changes constantly or very often (a countdown watch, for example) and causes the DOM tree to refresh on every second. When in frozen state you can use the Refresh Elements Tree button to update the elements tree manually.
4. Search Bar
You can search for an element in the DOM. You can use the arrow buttons to jump to the next or previous element that matches your search criteria.
Tip
Use # for find expression
5. Elements Tree and Tag View
The tree view lists elements in their original hierarchy order and the tag view groups them by their TagName.
6. Parent Element Filter
This field contains entries for the entire page and for iFrame elements within the page. This field is missing if there is only one parent element (i.e. the Page node).
Element Context Menu
The DOM Explorer provides few element based options in a context menu. Right click on any element and choose from the available operations.
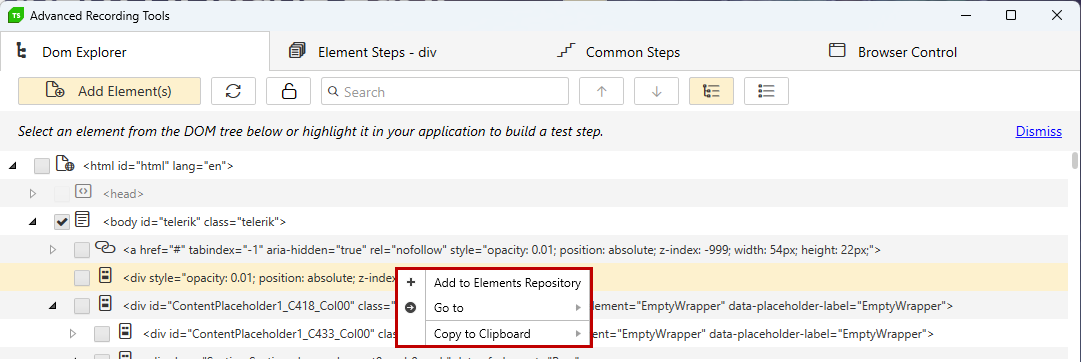
Add to Elements Repository - adds the selected element to the Elements Explorer in the project.
Goto - navigate to a parent element. Sample entries include the entire page or an iFrame element within the page.
Copy to Clipboard - copy the DOM element as HTML. Choose either "Tag Only" or "Tag and Children" depending on what you need to copy - the specific element only or also all its nested elements.
Searching For Elements
The DOM Explorer allows you to search for elements in the entire DOM tree. A simple text search may not alywas have enough horsepower to locate elements nested deep in a large and complex DOM. For that reason, the Search Bar tool has rich element identification capabilities that range from simple searches by name to complex criteria expressed using XPath and Regular Expression. You can also use simple find expressions that test an element against a value.
Search Element Atributes
You can use any valid attribute name (i.e. "id", "div", "name", etc.), or any of the following:
TextContent - returns an element that has certain text within it. TextContent is only the text at the same level as the node.
InnerText - looks for text content inside some set of element tags. Innertext is the combined text for a given node and everything below it.
InnerMarkup - returns an element with specific HTML markup inside it.
OuterMarkup - looks for specific HTML markup inclusive of the element itself.
StartTagContent
NodeIndexPath
TagName
TagIndex (zero based)
XPath - XML Path Language expressions, a syntax for selecting elements in an XML document. See MSDN for examples.
Search Operators
Append an additional operator to the "=" to make other comparisons.
~ Contains
! NotContain
^ StartsWith
? EndsWith
# RegEx
, And
Here is an example that searches for the "type" attribute that contains "hidden".
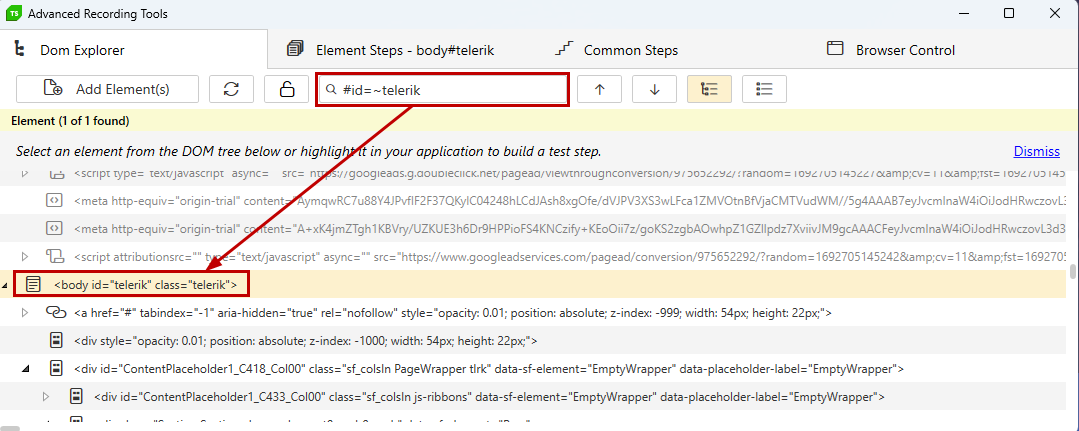
Regular Expressions
Regular Expressions (RegEx) are a sequence of text characters used to describe a search pattern. They are somewhat akin to "wildcard" characters, i.e. "*" or "?", but are much more flexible and powerful. Regular expressions in Test Studio start with the "#" character. See MSDN for examples.
Below picture demonstrates an example that searches for the "onsubmit" attribute that contains the word "myFunction".